



Crypitor - Monitoring the Crypto World

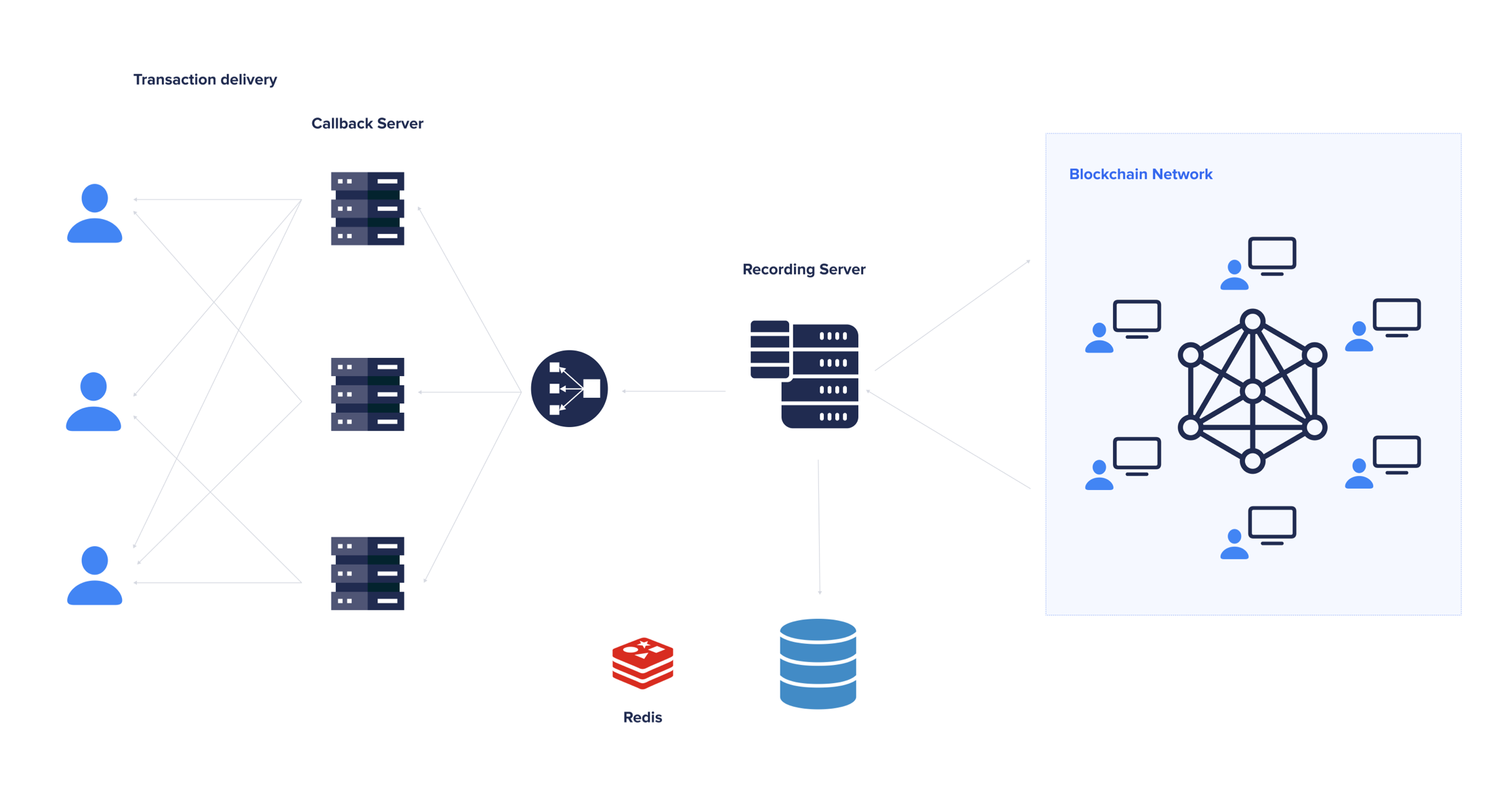
Overview
At the very first stage of development, Crypitor has comprehended that building up a scalable service without downtime is the biggest challenge. So they have asked the OpsSpark team to design the whole system from scratch.
Challenges
- As Crypitor serves large-scale enterprises, the webhook system has to be able to handle 1M requests per second.
- Crypitor service has to handle dynamically increasing requests, so the system must be able to scale up and down automatically
- The system needs to be updated at a quicker pace to adapt to technological changes
- The operations team will control the tech stack while developers distribute and monitor data
- The system has to ensure that the services run without downtime
- DevOps team has to set up, maintain and monitor Blockchain nodes such as Ethereum, EOS, and Ripple which were very unstable at this time.
Solution
With the wide range of operations knowledge, the OpsSpark tech team has collaborated with the Crypitor team to speed up the deployment as well as service development.
CI/CD pipeline implementation
The Crypitor team uses Github for deployment so our tech team has decided to use Github actions to build and deploy the system to the Google Cloud Platform. The technology stack is Java, Maven, Apache Tomcat, VueJS, Redis, webhook.site…
For the backend stack, the OpsSpark team used Docker to containerize the webhook applications, and put the whole software into the COS image on the Container Registry, the image is deployed on the GCP Managed Instance group.
For the frontend stack, we put all static files on Google Firebase with caching best practices, to deploy, manage and revert content easily, without interruption.
For configuration management and application deployment, we used Bash Script and Ansible.
Requests handling
To achieve proper load balancing, traffic distribution, and HTTP caching across the customer’s IT infrastructure, our DevOps engineers used the following tools:
- GCP Load Balancer - to distribute the requests across servers in managed instance group
- GCP Instance Group - to scale up automatically on the number of requests
- GCP Memorystore - to make sure the Redis can handle a huge amount of transactions
Log management, monitoring, and alerts
The application service logs are sent to Stackdriver, which allows the Crypitor team to easily access the GCP console.
For resource monitoring, our engineers have set up and applied a Prometheus agent and centralized logs on Grafana dashboards.
For uptime monitoring, the OpsSpark team used Python Scripts to monitor web services availability and send important alerts to a Telegram channel.
Security
We used Cloudflare as the first endpoint to handle incoming traffic to protect the website against fraud connections. Each environment's testing, staging, and production environment use its own separated VPC Networking. All accesses to the internal backend and database need to be through VPN.
Achievement
- The Blockchain webhook service is able to handle infinite traffic and workloads, we have tested that the service can handle 1M requests per second.
- The Crypitor team was able to manage their service securely, efficiently, and conveniently, with the high availability of the architecture.
- All fraud traffic is filtered at Cloudflare layer, Crypitor team can also track other logs on Stackdriver







